TensorFlow 1.12.0
Na računalnom klasteru Isabella, na čvorovima s grafičkim procesorima NVIDIA Tesla V100-SXM2-16GB, instalirana je Pythonova biblioteka za strojno učenje TensorFlow, verzija 1.12.0, optimizirana za izvođenje na grafičkim procesorima.
TensorFlow je preveden za Python 3.5, uz sljedeće verzije NVIDIA alata i biblioteka za strojno učenje:
- CUDA 10.0
- cuDNN 7.3.1
- NCCL 2.3.5
Pripremljen je modul koji postavlja sve potrebne varijable okoline:
| Verzija | Modul |
|---|---|
| 1.12.0 | tensorflow/1-12-0-gpu |
Izvođenje poslova
U nastavku je opisano podnošenje tipičnih Python poslova. Više informacija o pokretanju poslova možete pronaći na stranicama Korištenje grafičkih procesora te Pokretanje i upravljanje poslovima.
Korištenje jednog grafičkog procesora:
Važno
U opisima poslova koji koriste jedan grafički procesor, obavezno treba koristiti cuda-wrapper.sh, kao u sljedećem primjeru:
#$ -cwd #$ -pe gpu 1 module load tensorflow/1-12-0-gpu cuda-wrapper.sh python3.5 moj_program.py
Korištenje više grafičkih procesora:
Korištenje više grafičkih procesora nije dopušteno bez korištenja biblioteke Horovod.
U opisima poslova koji koriste više grafičkih procesora, obavezno treba koristiti openmpi-wrapper.sh, kao u primjerima u nastavku.
Korištenje više grafičkih procesora na jednom čvoru:
Za pokretanje poslova koji zahtijevaju više grafičkih procesora na jednom čvoru potrebno je koristiti paralelnu okolinu gpusingle te željeni broj grafičkih procesora (maksimalno 4):
#$ -cwd #$ -pe gpusingle 4 module load tensorflow/1-12-0-gpu openmpi-wrapper.sh python3.5 moj_program.py
Korištenje više grafičkih procesora na više čvorova:
#$ -cwd #$ -pe gpu 6 module load tensorflow/1-12-0-gpu openmpi-wrapper.sh python3.5 moj_program.py
Korištenje cijelih čvorova s grafičkim procesorima
Za pokretanje poslova koji zahtijevaju cijele čvorove potrebno je koristiti paralelnu okolinu gpufull te željeni broj grafičkih procesora (mora biti djelitelj broja 4). Primjer skripte za zauzimanje dva čvora:
#$ -cwd #$ -pe gpufull 8 module load tensorflow/1-12-0-gpu openmpi-wrapper.sh python3.5 moj_program.py
Podnošenje posla
Posao se podnosi s pristupnog čvora naredbom:
qsub tf.sge
Performanse
Performanse paralelnog izvođenja TensorFlow aplikacija korištenjem biblioteke Horovod mjerene su standarnim resnet101 benchmarkom iz službenog TensorFlow benchmark repozitorija.
Slika 1 prikazuje performanse na resnet101 testu u odnosu na broj GPU-ova. Vidljivo je da se s povećanjem broja GPU-ova povećava gubitak u odnosu na maksimalne teoretske performanse, što je i za očekivati. Međutim, čak i za 12 GPU-ova, sustav daje oko 85% idealnog slučaja. Idealne performanse procijenjene su iz rezultata istog benchmarka na jednom grafičkom procesoru, bez korištenja biblioteke Horovod.

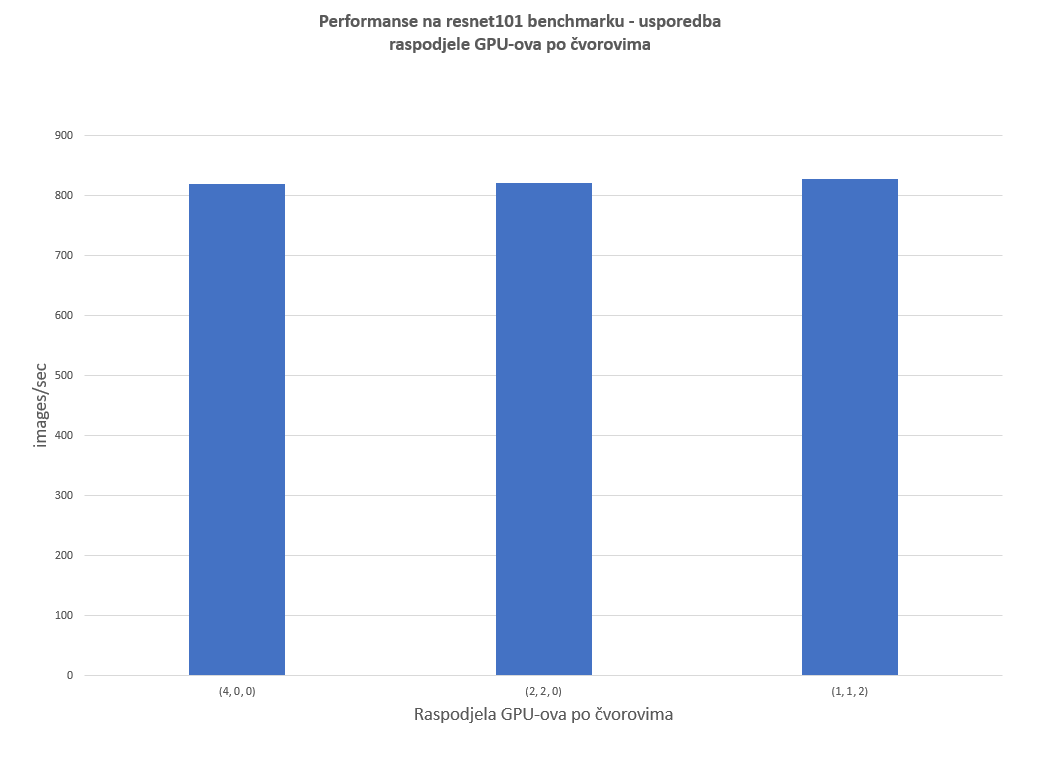
Slika 2 prikazuje performanse na istom benchmarku, korištenjem 4 GPU-a u različitim raspodjelama po čvorovima. Vidljivo je da raspored GPU-ova po čvorovima ne utječe bitno na performanse na ovom benchmarku.