Na ovoj stranici možete naći upute i prijedloge o korištenju pythona, pipa i conde na Supeku:
- Lustre i virtualna okruženja - Kako se virtualna okruženja ponašaju na datotečnom sustavu Lustre
- Apptainer i kontejnerizacija - Poželjan način dopremanja i korištenja virtualnih okruženja
- Primjeri - Primjeri stvaranja kontejnera za određene aplikacije
- Kako dalje? - Reference s dodatnim detaljima
Prva dva poglavlja plitku su uvod u potrebu kontejnera pri korištenju python knjižnica na Supeku, dok su druga dva posvećena naputcima (za nestrpljive) i referencama za one koji žele ući dublje u načine na koje se to može ostvariti.
Lustre i virtualna okruženja
Uvod
Lustre je paralelni raspodijeljeni datotečni sustav koji koristi Supek, namijenjen okruženju HPC u kojem veliki broj korisnika generira i koristi iznimnu količinu podataka, i čija je visoka dostupnost i brzina prijenosa bitna radi što efikasnijeg izvođenja paralelnih aplikacija.
Način na koji ovo postiže je fizičkim razdvajanjem opisa datotečnog sustava (tzv. namespacea ) od njegovog stvarnog sadržaja (u objektnom obliku) koji je na Supeku pohranjen na stotinjak SSD-ova u tehničkoj izvedbi ClusterStor E1000.
Lustre datotečni sustav se sastoji od nekoliko glavnih komponenata (s pripadnim dijagramom ispod):
- Metadata Server - Poslužitelji za upravljanje pohranjenim podacima s informacijama poput njihovog imena, vlasništva i prava pristupa
- Object Storage Server - Poslužitelji na kojima se podaci fizički nalaze i koji se mogu proizvoljno skalirati
- Management Server - Poslužitelji koji su odgovorni za nadzor i upravljanje cjelokupnim datotečnim sustavom Lustre
- Lustre Networking - Brza i visoko propusna veza kojom se podaci prenose
- Client - Mount point na pristupnim poslužiteljima koji otkriva datotečni sustav Lustre korisničkim aplikacijama
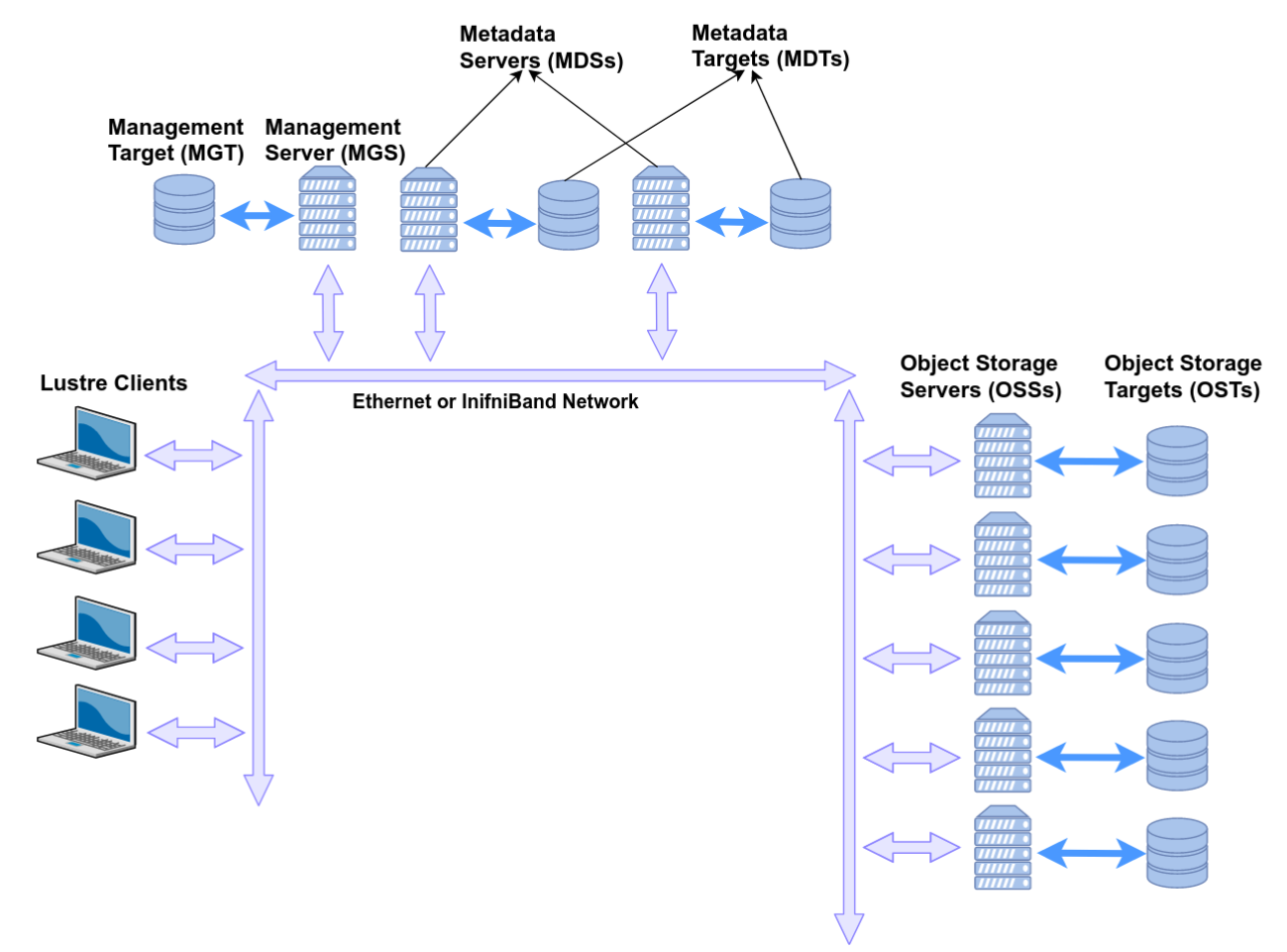
Slika 1. Dijagram datotečnog sustava Lustre (Figure 1 u izvornoj publikaciji)
Kako Lustre radi i kako ga pravilno koristiti
Pri svakoj datotečnoj operaciji čitanja ili pisanja, klijent šalje zahtjev Metadata Serveru na kojem se nalazi virtualni zapis opisa i lokacija pravog podatka raspodijeljenog na više Object Storage Servera. Jednom kada se tražena datoteka (ili datoteke) pronađu, stvara se direktna veza između klijenta i fizičkog zapisa, koja osigurava pristup i njeno daljnje upravljanje.
U višekorisničkom okruženju poput klastera Supek, pristup i upravljanje podataka mora biti usklađeno i koherentno svakoj korisničkoj aplikaciji koja im pristupa. Ovo se postiže naizmjeničnim osvježavanjem i usklađivanjem virtualnog zapisa koje ima svoje granice optimalnog izvođenja, iznad kojeg se performanse drastično smanjuju za cijeli datotečni sustav kojim se upravlja.
Neke od preporuka za Lustre dijeljeni datotečni sustav uključuju:
- štedljivo korištenje naredbi za opis datotečnog sustava poput
ls, find, duilidf - izbjegavanje osobnog prevođenja i instalacije aplikacija
- izbjegavanje pokretanja izvršnih datoteka s datotečnog sustava Lustre
- izbjegavanje direktorija s velikim brojem datoteka (optimalno je manje od tisuću) ili datotekama malog obujma (optimalno više od 1GB)
Ispod se nalazi primjer čitanja sadržaja direktorija komandom ls -l * stotinu puta zaredom (što je tipično opterećenje jednog klastera) nad raznim kombinacijama broja direktorija i datoteka koje zajedno sadrže 10GB podataka. Najintenzivnije usporavanje postiže se povećanjem broja direktorija (x40-50) naspram broja datoteka (x4-5), koje ukazuje na nužnost agregacije što većeg broja datoteka u u što manje direktorija; idealno u datoteke većeg obujma.

Slika 2. Vrijeme izvođenja komande ls -l * nad kombinacijama broja
direktorija (1-1000) i datoteka (1-100)
Python i virtualna okruženja
Python knjižnice danas se većinom instaliraju korištenjem aplikacija pip ili conda; upraviteljima knjižnica koji osiguravaju dopremanje svih ovisnosti potrebnih za instalaciju i razvoj aplikacija python.
Iako ove aplikacije pružaju veoma jednostavno i efikasno okruženje za brzi razvoj i eksperimentiranje raznih knjižnica i njihovih kombinacija, svakom novom instalacijom broj datoteka se multiplicira i dodatno opterećuje dijeljeni sustav (učestalim čitanjem i pisanjem pri razvoju ili izvršavanju)
Ispod se nalazi primjer okruženja nastalog pip instalacijama za samo jednu verziju pythona, koje u sebi sadrži tipični data stack u kojem se nalazi (approx.):
- 4000 direktorija
- 15 datoteka po direktoriju
- 2G podataka
Ako pretpostavimo slična ubrzanja iz prethodnog dijagrama, Lustre datotečni sustav možemo potencijalno koristiti i do deset puta efikasnije (ili barem jedan značajan dio njegove funkcionalnosti) ako okrupnimo podatke u jednu veću, zasebnu cjelinu.
Tablica 1. Ispis broja direktorija, broja datoteka koje sadrže i njihove
veličine za tipičan python3.9 data stack.
marko@pc-mkvakic 15:05 ~ $ find ~/.local/lib/python3.9/site-packages /usr/local/lib/python3.9/dist-packages -type d | wc -l 4338 marko@pc-mkvakic 15:05 ~ $ find ~/.local/lib/python3.9/site-packages /usr/local/lib/python3.9/dist-packages -type f | wc -l 47355 marko@pc-mkvakic 15:06 ~ $ du -hcs ~/.local/lib/python3.9/site-packages /usr/local/lib/python3.9/dist-packages 939M /home/marko/.local/lib/python3.9/site-packages 747M /usr/local/lib/python3.9/dist-packages 1.7G total
Apptainer i kontejnerizacija
Ustaljen način dopremanja i stvaranja korisničkih okolina danas
Primjeri
Kako dalje?
- Najbolje prakse na ostalim