Opis
ORCA je računalno-kemijska aplikacija općenitog tipa koji nudi širok raspon metoda.
ORCA je zatvorenog koda i dolazi s Open MPI implementacijom MPI-ja.
Verzije
| Verzija | Modul | Podrška | Paralelizacija | Supek | Padobran |
|---|---|---|---|---|---|
| 4.2.1 | scientific/orca/4.2.1 | CPU | Open MPI 3 | ||
| 5.0.3 | scientific/orca/5.0.3 | CPU | Open MPI 4 | ||
| 5.0.4 | scientific/orca/5.0.4 | CPU | Open MPI 4 | ||
| 5.0.4 | scientific/orca/5.0.4-openmpi5 | CPU | Open MPI 5 | ||
| 6.0.0 | scientific/orca/6.0.0 | CPU | Open MPI 4 | ||
| 6.0.0 | scientific/orca/6.0.0-openmpi5 | CPU | Open MPI 5 |
ORCA dolazi u obliku prekompajliranih izvršnih datoteka koje se povezuju na Open MPI knjižnice.
Službena dokumentacija
- https://www.orcasoftware.de/tutorials_orca/#
- https://orcaforum.kofo.mpg.de/app.php/portal
- ORCA 5.0.4 priručnik
Primjeri korištenja na Supeku i Padobranu
Zbog nemogućnosti starijih verzija Open MPI-ja da iskoriste puni potencijal Supekove Slingshot mreže, odnosno nemogućnosti širenja van jednog čvora u slučaju Padobrana, potrebno je aplikaciju zadržati unutar granica jednog čvora, koristeći PBS opciju:
#PBS -l place=pack
To nije slučaj kod modula scientific/orca/*-openmpi5, koji se na Supeku može pokretati i bez gore navedene opcije, odnosno omogućuje širenje aplikacije van jednog čvora.
ORCA-ina varijabla MaxCore (definirana u input datoteci) predstavlja memorijsko ograničenje određenih ORCA-inih računskih funkcija. Premala vrijednost za složenije sustave može rezultirati prekidom izvođenja posla. Tako primjerice %MaxCore 4000 postavlja ograničenje od 4000 MB i primjenjuje se po procesorskoj jezgri.
Međutim, program može i zauzeti više od toga pa se savjetuje koristiti broj koji je oko 75% zatražene memorije (po selectu) u zaglavlju PBS skripte.
Pokretanje s ${ORCA_ROOT}/orca
Broj procesorskih jezgri ili radne memorije u ulaznu (.inp) datoteku možete unijeti ručno.
U primjeru niže, aplikacija će se pokrenuti sa 16 MPI procesa.
#PBS -q cpu
#PBS -l select=16:mem=5000mb
#PBS -l place=pack
cd ${PBS_O_WORKDIR}
module load scientific/orca/5.0.4
${ORCA_ROOT}/orca hydrolysis.inp
Prije pokretanja skripte, nužno je prilagoditi input datoteku:
!B3LYP DEF2-SVP D4 NEB-TS %pal nprocs 16 end %maxcore 3932 %NEB NEB_END_XYZFILE "products.xyz" PREOPT_ENDS TRUE END * XYZfile 0 1 reactants.xyz
Pokretanje s runorca.mpi
Kao jednostavnija alternativa, izrađena je skripta runorca.mpi
Skripta će prije pokretanja ORCA-ine izvršne datoteke izmijeniti input, odnosno njegove %pal i %maxcore linije u skladu sa zaglavljem, odnosno definiranim brojem procesorskih jezgara i memorijom (maxcore vrijednost se automatski postavlja kao 75% mem vrijednosti po procesorskoj jezgri). Iz tog razloga, te linije možete izostaviti iz "izvorne" input datoteke.
Uz to, skripta će implementirati korištenje TMPDIR direktorija, što u slučaju Padobrana dodatno može značiti i postizanje boljih performansi.
#PBS -q cpu
#PBS -l select=16:mem=5000mb
#PBS -l place=pack
cd ${PBS_O_WORKDIR}
module load scientific/orca/5.0.4
runorca.mpi --input hydrolysis.inp
!B3LYP DEF2-SVP D4 NEB-TS %NEB NEB_END_XYZFILE "products.xyz" PREOPT_ENDS TRUE END * XYZfile 0 1 reactants.xyz
Usporedba ORCA 6 v. ORCA 5
Citat, Release Notes ORCA 6.0.0:
U ORCA-i 6, napravljene su velike promjene u kodu koje su učinile cijeli program bržim, robusnijim i manje memorijski zahtjevnim u usporedbi s prethodnim verzijama ORCA-e.
U nastavku su prikazane usporedbe identičnih, tipičnih ORCA izračuna. Korišten je sustav uobičajene složenosti, odnosno organski spoj s oko stotinu atoma.




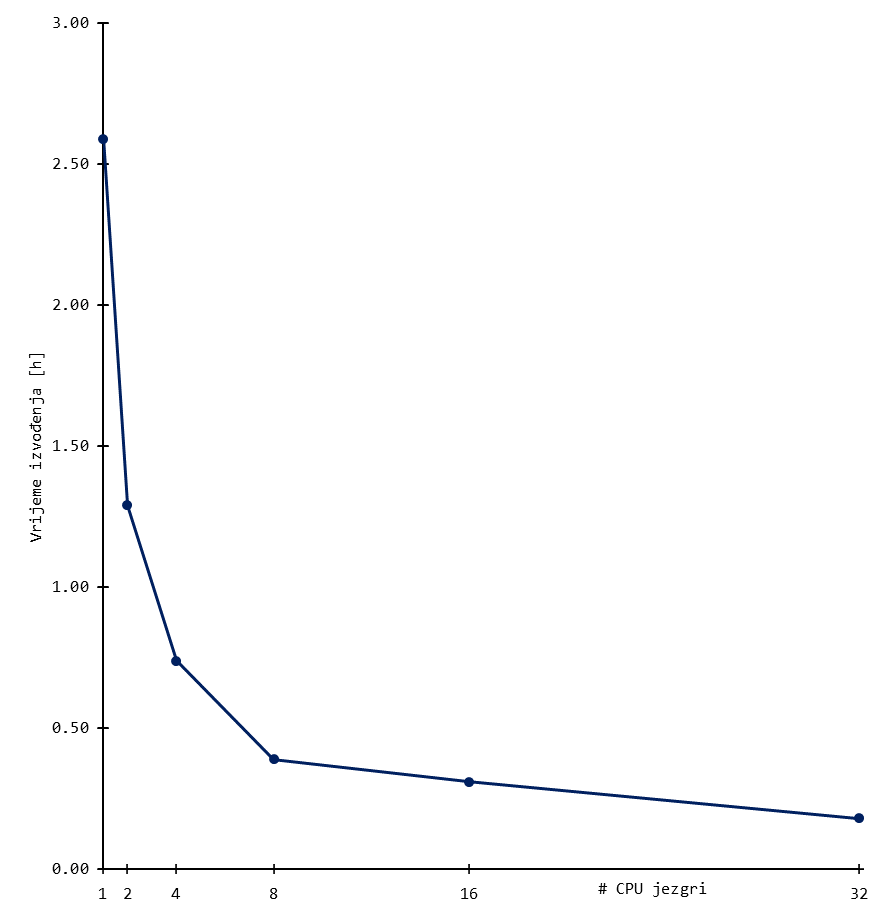
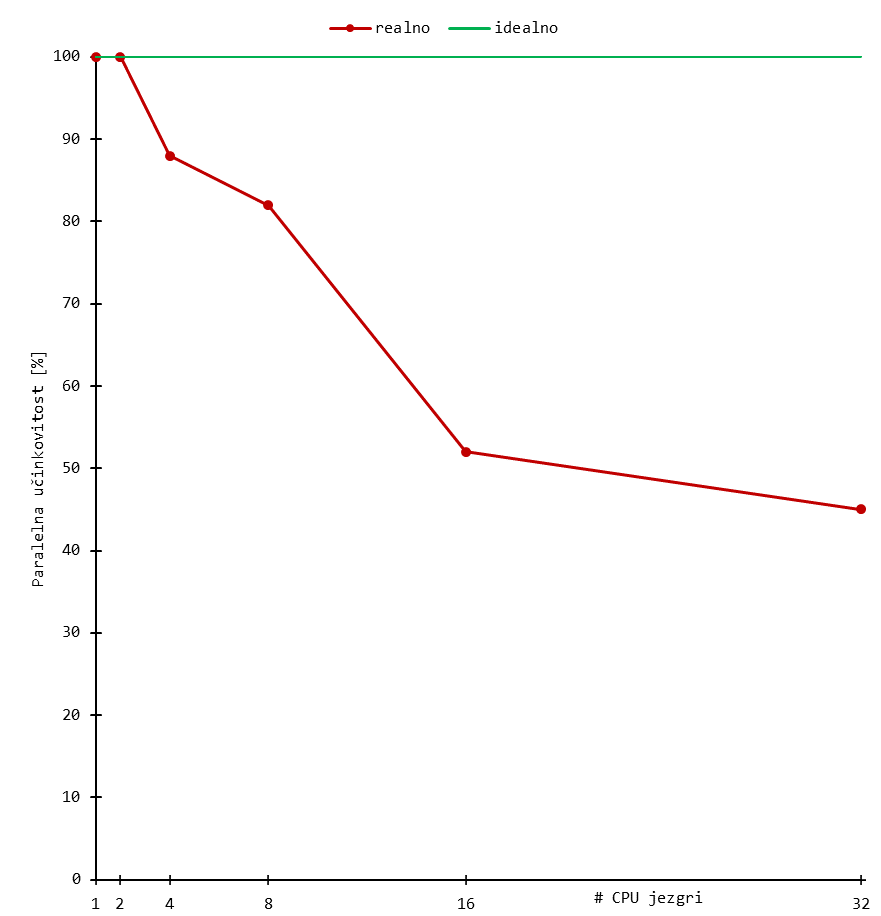
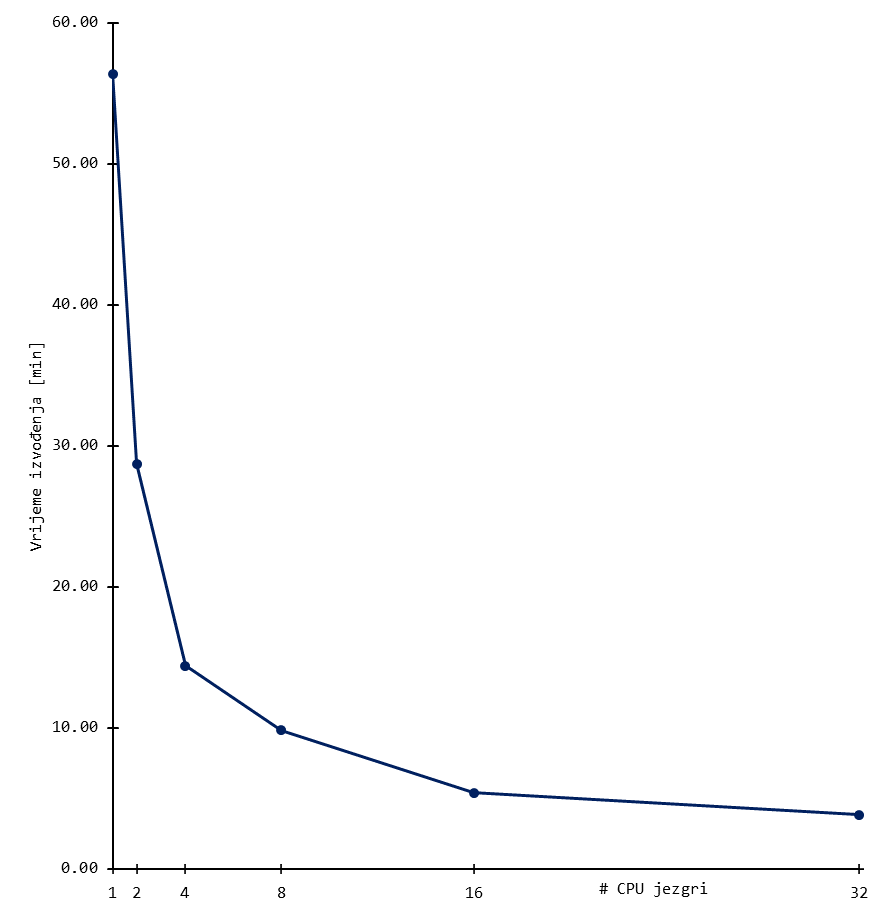
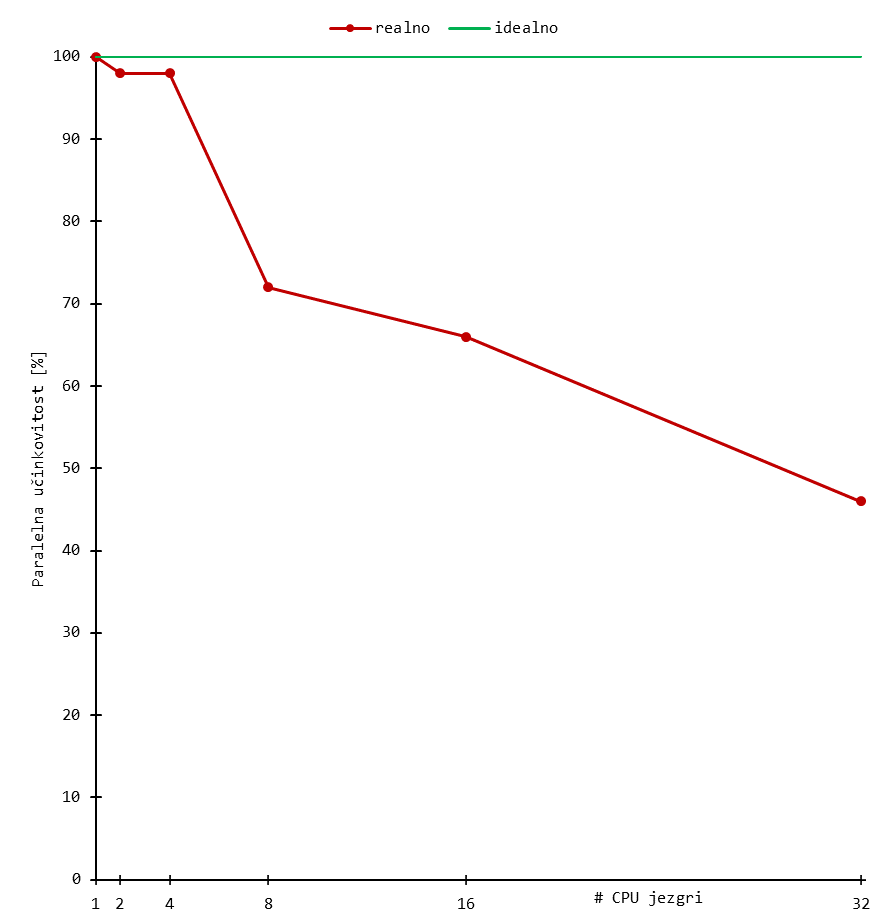
Skaliranje
Niže su prikazani rezultati bencmarka za tipične ORCA izračune. Korišten je sustav uobičajene složenosti, odnosno organski spoj od stotinjak atoma.
Rezultati daju grubi uvid u skaliranje aplikacije, a mogu se tumačiti kao orijentacijske vrijednosti broja procesorskih (CPU) jezgri.
Skalabilnost značajnije pada nakon otprilike 16 jezgri (i ponekad ranije) za sustav tipične složenosti. Daljnje povećanje procesorskih jezgri dovodi do marginalnih povećanja performansi, a učinkovitost korištenja resursa pada.
Stoga se preporuča koristiti manji broj jezgri i radije pokrenuti više poslova za isti set slobodnih resursa budući da se tako koristi učinkovitije.
Dugoročno korištenje većeg broja CPU jezgri povećava Vaš udio CPU walltime-a u ukupnom (klasterskom) CPU walltime-u, što negativno utječe na Vaš fairshare udio.
! B3LYP/G 6-31G** D3BJ ENGRAD
! B3LYP/G 6-31G** D3BJ FREQ
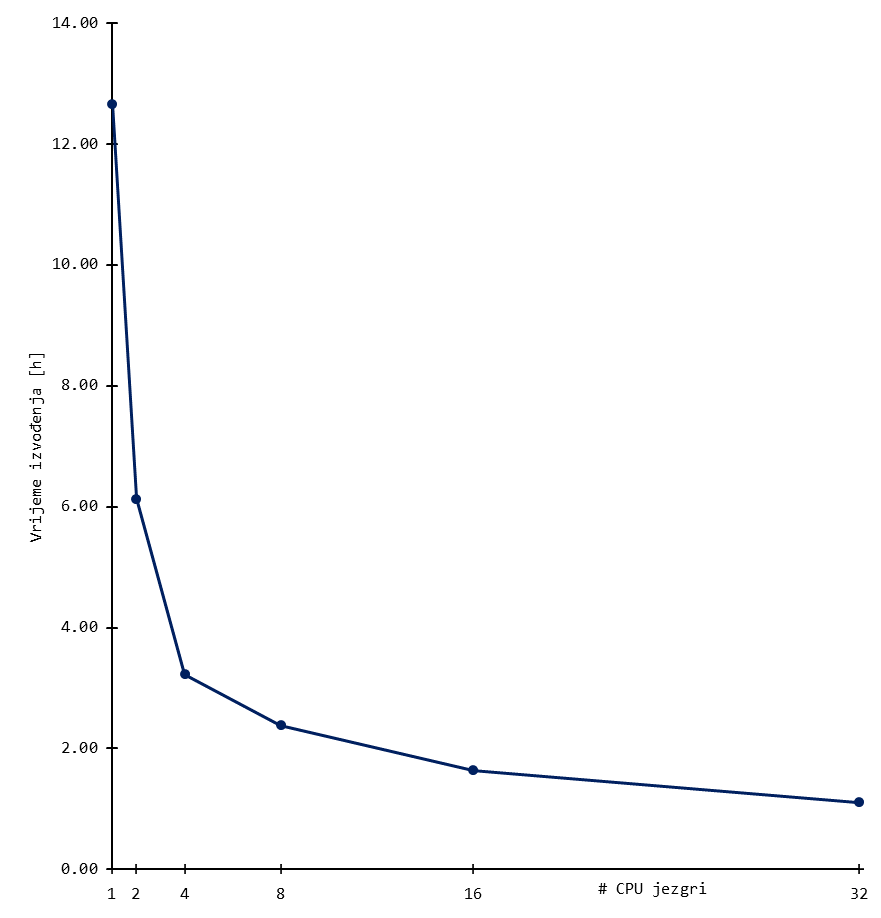
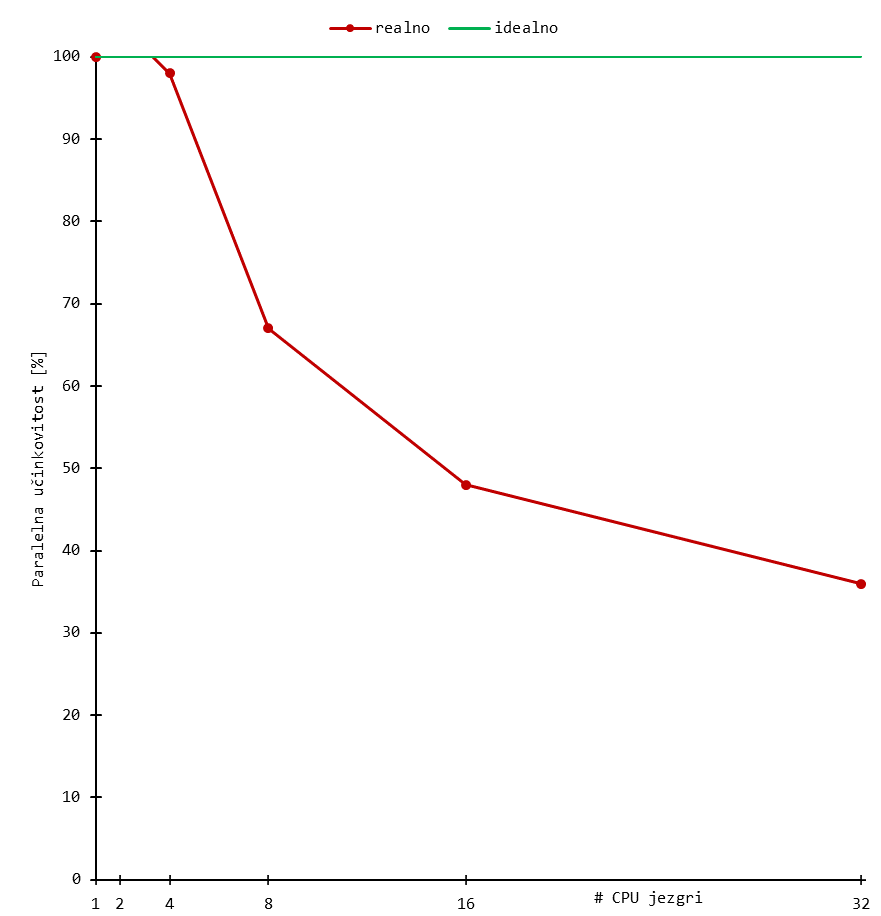
! B3LYP/G 6-311+G** D3BJ NMR
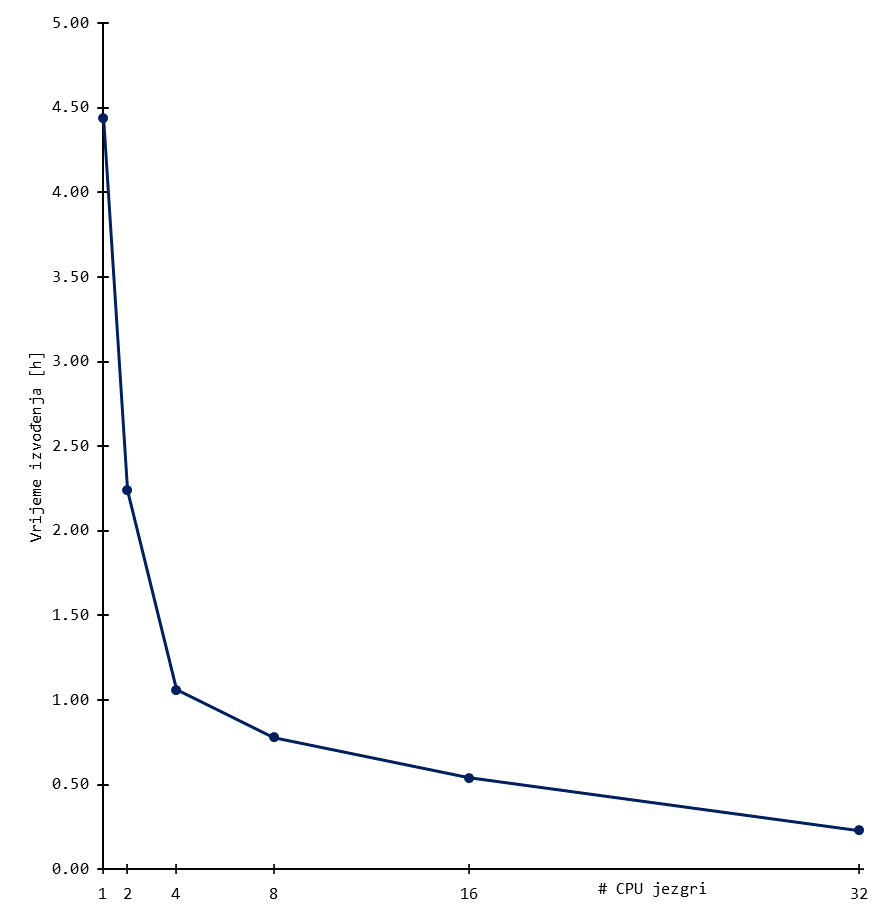
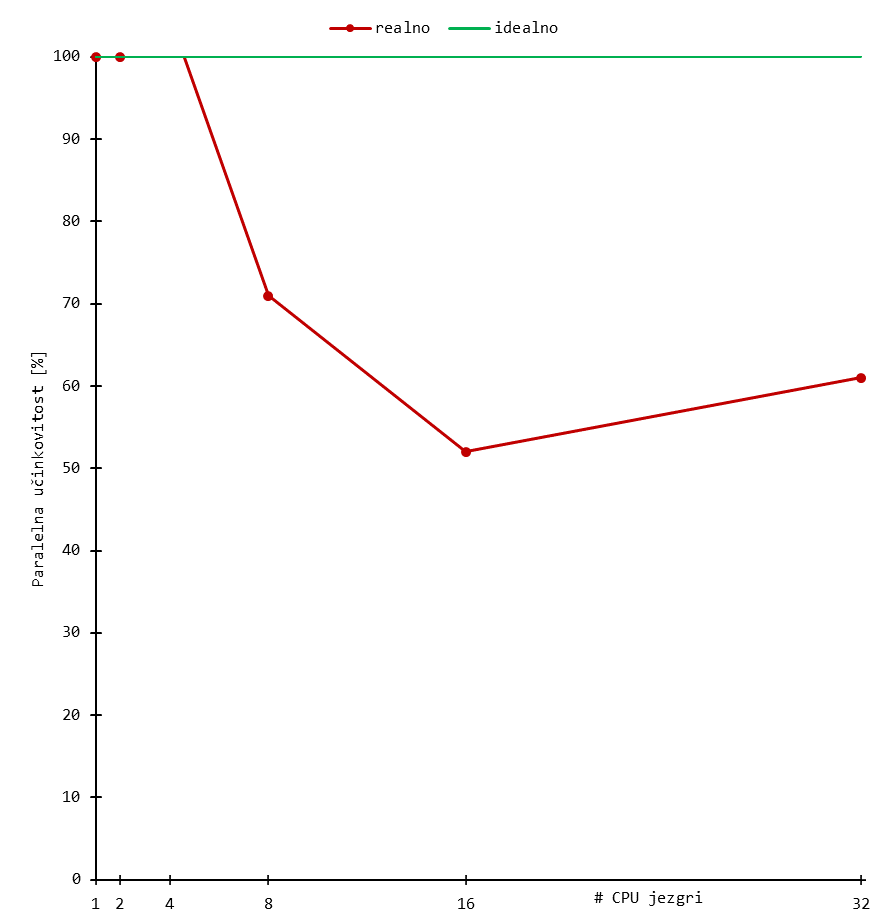
! B3LYP/G 6-31+G** D3BJ, %tddft nroots=8 end